Kiedy mówimy o sprzedaży danych użytkowników, rzadko zastanawiamy się, jak głęboko mogą sięgać konsekwencje takich transakcji. Z najnowszych informacji, do jakich dotarłem, wynika, że popularne platformy Tumblr i WordPress ? należące do firmy Automattic ? mogły podjąć kroki, które wpisują się w obawy wielu z nas.
To budzi szereg pytań, nie tylko etycznych, ale i prawnych. W jaki sposób gromadzone są te dane? Kto za tym stoi i czy użytkownicy mają świadomość, na co wyrażają zgodę, przesyłając swoje wpisy na wymienionych platformach?
Spis treści
- Zapowiedź kontrowersyjnej współpracy Tumblr i WordPress z firmami AI
- Jakie dane użytkowników są zagrożone?
- Dane z blogów hostowanych na platformie WordPress.com
- Publiczne wpisy od 2014 do 2023 roku
- Prywatne posty i zawartość z usuniętych blogów
- Pytania bez odpowiedzi
- Prywatne odpowiedzi
- Posty NSFW
- Posty z kont partnerskich, takie jak kampanie reklamowe, do których Tumblr nie posiada praw. (Apple jest tu konkretnie wymienione)
- Krytyka społeczności twórczej i prawne ryzyko ?scrapowania? danych
- FAQ
- Czy Automattic ma zamiar sprzedawać dane użytkowników z Tumblr i WordPress do szkolenia narzędzi AI?
- Jakie informacje ujawnił 404 Media odnośnie współpracy Automattic z firmami AI?
- Jakiego rodzaju dane użytkowników Tumblr mogą być zagrożone w wyniku współpracy z firmami AI?
- Jakie zmiany planuje wprowadzić Automattic w odpowiedzi na kontrowersje związane z prywatnością danych?
- Jak społeczność twórczą reaguje na plany wykorzystania ich pracy do celów szkolenia narzędzi AI?
- Jakie jest prawne ryzyko związane ze scrapowaniem danych do szkolenia sztucznej inteligencji?
- Linki do źródeł
Kluczowe wnioski
- Automattic, właściciel Tumblr oraz WordPress.com, może uczestniczyć w sprzedaży danych użytkowników podmiotom takim jak OpenAI oraz Midjourney.
- Autommatic podkreślił, że scrapowane dane dotyczą tylko blogów opartych na platformie wordpress.com, nie na wszystkich serwisach opartych o CMS wordpress hostowanych gdzie indziej, nawet jeśli korzystają z wtyczek od Automattic takich jak np. Jetpack
- Proces przekazywania danych wydaje się nie tylko kontrowersyjny, ale i ryzykowny dla prywatności użytkowników.
- Pojawiają się głosy sprzeciwu i niepokój wśród społeczności kreatywnej.
Zapowiedź kontrowersyjnej współpracy Tumblr i WordPress z firmami AI
Z najnowszych informacji wynika, iż Automattic, właściciel platform takich jak Tumblr i WordPress.com, wykazuje zainteresowanie w sprzedaży danych użytkowników. Planowane działania są częścią większego projektu współpracy z AI, które mają być realizowane razem z wiodącymi firmami technologicznymi takimi jak OpenAI czy Midjourney. Jako pierwsza o szczegółach transakcji napisała redakcja 404 Media, powołując się na anonimowe źródła.
Jednakże, z informacji wynika, że owa współpraca może rodzić wiele zagrożeń dla prywatności internautów.
404 Media ujawnia plany Automattic
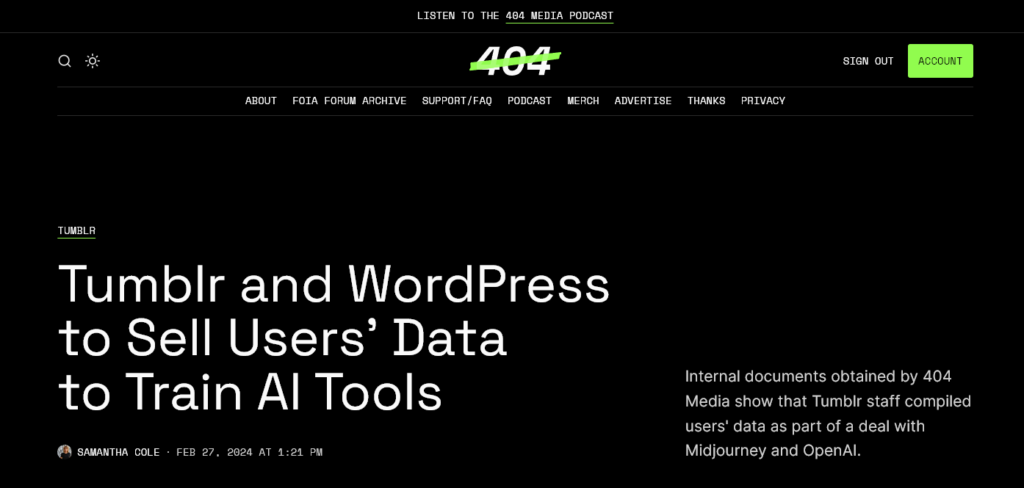
Opierając się na dokumentach 404 Media, współpraca z firmami specjalizującymi się w sztucznej inteligencji ma na celu ulepszenie narzędzi wykorzystywanych przez obie platformy.
Wewnętrzny post menedżera produktu w Tumblr (Cyle Gage) i jego konsekwencje
Iskra, która wywołała tę dyskusję, zapłonęła po wewnętrznym poście jednego z menedżerów produktu w Tumblr (Cyle Gage). Wyraził on swoje obawy dotyczące zakresu danych, które mieliby zdobyć partnerzy AI, co może mieć bezpośrednie konsekwencje dla poziomu zaufania użytkowników platformy.
Oryginalny wpis Cyle Cage?a:
?the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr?s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
- private posts on public blogs
- posts on deleted or suspended blogs
- unanswered asks (normally these are not public until they?re answered)
- private answers (these only show up to the receiver and are not public)
- posts that are marked ?explicit? / NSFW / ?mature? by our more modern standards (this may not be a big deal, I don?t know)
- content from premium partner blogs (special brand blogs like Apple?s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn?t belong to us, and we don?t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.?
Jakie dane użytkowników są zagrożone?
Dane z blogów hostowanych na platformie WordPress.com
Automattic określa, że tylko witryny WordPress.com są dotknięte tym scrapowaniem danych, w przeciwieństwie do treści utworzonych w CMS WordPress, których można używać w witrynie hostowanej gdzie indziej.
Publiczne wpisy od 2014 do 2023 roku
Analiza dokumentów wykazała, że wpisy publiczne mogą być niecelowo przekazywane firmom zewnętrznym. Szczególnie narażone są posty udostępniane na blogach w okresie od 2014 do 2023 roku, które pomimo publicznego charakteru, nie powinny być wykorzystywane bez wyraźnej zgody autorów.
Prywatne posty i zawartość z usuniętych blogów
Prywatne komunikaty i treści pochodzące z blogów, które zostały usunięte, również znalazły się na liście zagrożeń. Użytkownicy, którzy nieśli nadzieję, że ich dane zostały na stałe wycofane z sieci, teraz stoją przed możliwością nieautoryzowanego ujawnienia swoich informacji.
Pytania bez odpowiedzi
Prywatne odpowiedzi
Posty NSFW
Posty z kont partnerskich, takie jak kampanie reklamowe, do których Tumblr nie posiada praw. (Apple jest tu konkretnie wymienione)
Żądania dotyczące zmian w polityce prywatności Automattic
Automattic, jako właściciel platform takich jak WordPress.com i Tumblr, stoi w obliczu rosnących oczekiwań w zakresie ochrony danych i poszanowania praw użytkowników. W najnowszych odpowiedziach na kontrowersje, firma zapowiada wprowadzenie zmian w swojej polityce prywatności, które dadzą osobom korzystającym z ich usług więcej kontroli nad tym, jak ich dane są wykorzystywane przez podmioty trzecie, w tym przez rozwijające się technologie oparte o sztuczną inteligencję.
?We are also working directly with select AI companies as long as their plans align with what our community cares about: attribution, opt-outs, and control.
- We will only share public content that?s hosted on WordPress.com and Tumblr, and only from sites that haven?t opted out.
- We are not including content from sites hosted elsewhere even if they use Automattic plugins like Jetpack or WooCommerce.
Our partnerships will respect all opt-out settings. We also plan to take that a step further and regularly update any partners about people who newly opt out and ask that their content be removed from past sources and future training.? – Źródło: Automattic.com
Wprowadzając nową opcję opt-out, Automattic pozwoli użytkownikom zdecydować, czy chcą, aby ich treść była indeksowana przez zewnętrzne narzędzia AI. Ta zmiana jest zasadnicza dla zachowania autonomii i prywatności w sieci – osobiste dane, publikacje na blogach, a także treści wrażliwe będą mogły pozostać poza zasięgiem algorytmów bez wyraźnej zgody ich właścicieli.
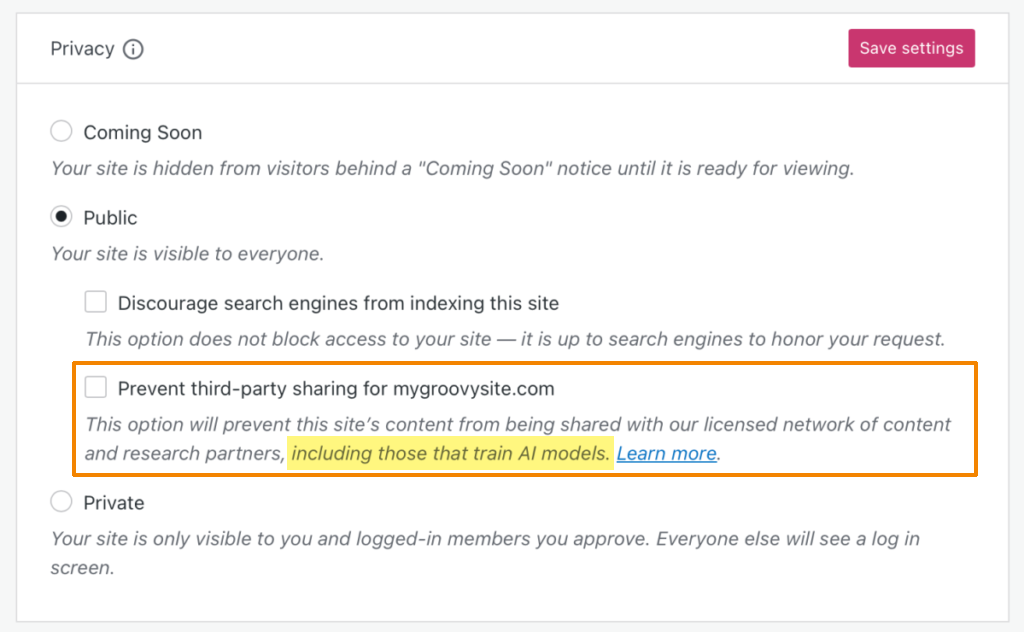
Andrew Spittle, szef ds. AI w Automattic odpowiedział także: ?We will notify existing partners on a regular basis about anyone who’s opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don’t think they gain much overall by retaining it.?
Krytyka społeczności twórczej i prawne ryzyko ?scrapowania? danych
Analizując różne przypadki, zauważyłem, że, chociaż firmy jak Reddit czy Shutterstock podjęły formalne kroki prawne, uzgadniając umowy umożliwiające wykorzystywanie treści użytkowników, wiele społeczności kreatywnych wciąż stoi na stanowisku, że nie zgadza się na takie działania. Problem staje się szczególnie istotny, gdy brane są pod uwagę materiały, które twórcy nie przeznaczyli do publicznego udostępniania, a co gorsza – prace, które miały charakter prywatny lub zostały usunięte przez użytkowników.
Ochrona praw autorskich w cyfrowym świecie staje się wyzwaniem, na które potrzebujemy skutecznych rozwiązań. Obserwuję to z zaciekawieniem, ponieważ rozwiązanie tego dylematu będzie mieć ogromny wpływ nie tylko na praktyki korporacyjne, ale przede wszystkim na poszanowanie twórczości i prawa własności intelektualnej. My, jako społeczeństwo cyfrowe, stajemy przed koniecznością zbalansowania postępu technologicznego z etycznym i prawnym wymiarem sztucznej inteligencji.
FAQ
Czy Automattic ma zamiar sprzedawać dane użytkowników z Tumblr i WordPress do szkolenia narzędzi AI?
Tak, według dokumentów uzyskanych przez 404 Media, istnieją plany sprzedaży danych użytkowników Tumblr i WordPress.com przez firmę Automattic do firm AI, w tym Midjourney i OpenAI, aby szkolić ich narzędzia.
Jakie informacje ujawnił 404 Media odnośnie współpracy Automattic z firmami AI?
404 Media ujawniło, że plany współpracy Automattic z firmami AI w ramach przekazania danych użytkowników są w trakcie finalizacji, ale nie zostały jeszcze precyzyjnie określone szczegóły dotyczące rodzajów danych, które zostaną przekazane.
Jakiego rodzaju dane użytkowników Tumblr mogą być zagrożone w wyniku współpracy z firmami AI?
Zagrożone są dane obejmujące prywatne posty, zawartość z usuniętych blogów, materiały NSFW oraz dane od partnerów, które zostały nieumyślnie zawarte w zestawieniu danych przekazanych firmom AI.
Jakie zmiany planuje wprowadzić Automattic w odpowiedzi na kontrowersje związane z prywatnością danych?
Automattic planuje zaimplementować nowe ustawienia prywatności, które umożliwią użytkownikom WordPressa i Tumblra kontrolę nad udostępnianiem ich danych trzecim stronom, w tym firmom AI. Użytkownicy będą mieli opcję opt-out, by zapobiec indeksowaniu ich treści przez narzędzia AI. Automattic zobowiązała się również kontaktować się z partnerami w celu usunięcia zawartości już wykorzystywanej przez firmy AI.
Jak społeczność twórczą reaguje na plany wykorzystania ich pracy do celów szkolenia narzędzi AI?
Artyści, pisarze i inni twórcy, zwłaszcza ci związani z Tumblr, wyrażają niezadowolenie i sprzeciw wobec wykorzystywania ich treści przez firmy AI bez ich zgody, obawiając się o naruszenie praw autorskich i utratę kontroli nad swoją pracą.
Jakie jest prawne ryzyko związane ze scrapowaniem danych do szkolenia sztucznej inteligencji?
Scrapowanie danych, czyli automatyczne zbieranie informacji z internetu, staje się coraz bardziej kontrowersyjne i ryzykowne z punktu widzenia prawa. Twórcy obawiają się naruszenia ich praw autorskich, a przypadki takie jak umowy zawarte przez Reddit czy Shutterstock z firmami AI podnoszą świadomość na temat potrzeby wyraźnej zgody na wykorzystanie danych do treningu AI.
Linki do źródeł
- https://www.404media.co/tumblr-and-wordpress-to-sell-users-data-to-train-ai-tools/
- https://automattic.com/2024/02/27/protecting-user-choice/
- https://www.theverge.com/2024/2/27/24084884/tumblr-midjourney-openai-training-data-deal-report
- https://lifehacker.com/tech/tumblr-and-wordpress-are-selling-your-data-to-ai-companies